



Every single day, some little piece of logic constructed by very particular bits of synthetic intelligence know-how makes selections that have an effect on the way you expertise the world. It may very well be the adverts that get served as much as you on social media or procuring websites, or the facial recognition that unlocks your cellphone, or the instructions you’re taking to get to wherever you are going. These discreet, unseen selections are being made largely by algorithms created by machine studying (ML), a section of synthetic intelligence know-how that’s educated to establish correlation between units of knowledge and their outcomes. We have been listening to in films and TV for years that computer systems management the world, however we have lastly reached the purpose the place the machines are making actual autonomous selections about stuff. Welcome to the long run, I assume. Earlier than that, if anybody is fascinated about upskilling their profile? Take up a acknowledged course in AI like Synthetic Intelligence On-line Course and chart your approach up professionally.
In my days as a staffer at Ars, I wrote no small quantity about synthetic intelligence and machine studying. I talked with information scientists who had been constructing predictive analytic programs based mostly on terabytes of telemetry from complicated programs, and I babbled with builders attempting to construct programs that may defend networks towards assaults—or, in sure circumstances, really stage these assaults. I’ve additionally poked on the edges of the know-how myself, utilizing code and {hardware} to plug numerous issues into AI programming interfaces (typically with horror-inducing outcomes, as demonstrated by Bearlexa).
Lots of the issues to which ML could be utilized are duties whose situations are apparent to people. That is as a result of we’re educated to note these issues by means of commentary—which cat is extra floofy or at what time of day site visitors will get probably the most congested. Different ML-appropriate issues may very well be solved by people as properly given sufficient uncooked information—if people had an ideal reminiscence, good eyesight, and an innate grasp of statistical modeling, that’s.
However machines can do these duties a lot quicker as a result of they do not have human limitations. And ML permits them to do these duties with out people having to program out the particular math concerned. As an alternative, an ML system can study (or at the least “study”) from the information given to it, making a problem-solving mannequin itself.
This bootstrappy power will also be a weak point, nonetheless. Understanding how the ML system arrived at its resolution course of is often inconceivable as soon as the ML algorithm is constructed (regardless of ongoing work to create explainable ML). And the standard of the outcomes relies upon a terrific deal on the standard and the amount of the information. ML can solely reply questions which might be discernible from the information itself. Unhealthy information or inadequate information yields inaccurate fashions and dangerous machine studying.
Commercial
Regardless of my prior adventures, I’ve by no means carried out any precise constructing of machine-learning programs. I am a jack of all tech trades, and whereas I am good on fundamental information analytics and operating all kinds of database queries, I don’t think about myself an information scientist or an ML programmer. My previous Python adventures are extra about hacking interfaces than creating them. And most of my coding and analytics abilities have, of late, been turned towards exploiting ML instruments for very particular functions associated to data safety analysis.
My solely actual superpower will not be being afraid to attempt to fail. And with that, readers, I’m right here to flex that superpower.
The duty at hand
Here’s a activity that some Ars writers are exceptionally good at: writing a strong headline. (Beth Mole, please report to gather your award.)
And headline writing is tough! It is a activity with numerous constraints—size being the most important (Ars headlines are restricted to 70 characters), however nowhere close to the one one. It’s a problem to cram right into a small house sufficient data to precisely and adequately tease a narrative, whereas additionally together with all of the issues it’s a must to put right into a headline (the standard “who, what, the place, when, why, and what number of” assortment of details). A few of the components are dynamic—a “who” or a “what” with a very lengthy identify that eats up the character depend can actually throw a wrench into issues.
Plus, we all know from expertise that Ars readers don’t like clickbait and can refill the feedback part with derision once they assume they see it. We additionally know that there are some issues that individuals will click on on with out fail. And we additionally know that whatever the matter, some headlines lead to extra individuals clicking on them than others. (Is that this clickbait? There is a philosophical argument there, however the major factor that separates “a headline everybody needs to click on on” from “clickbait” is the headline’s honesty—does the story beneath the headline totally ship on the headline’s promise?)
Regardless, we all know that some headlines are simpler than others as a result of we do A/B testing of headlines. Each Ars article begins with two attainable headlines assigned to it, after which the positioning presents each options on the house web page for a brief interval to see which one pulls in additional site visitors.
There have been a couple of research carried out by information scientists with way more expertise in information modeling and machine studying which have seemed into what distinguishes “clickbait” headlines (ones designed strictly for getting massive numbers of individuals to click on by means of to an article) from “good” headlines (ones that truly summarize the articles behind them successfully and do not make you write prolonged complaints in regards to the headlines on Twitter or within the feedback). However these research have been targeted on understanding the content material of the headlines relatively than what number of precise clicks they get.
Commercial
To get an image of what readers seem to love in a headline—and to attempt to perceive write higher headlines for the Ars viewers—I grabbed a set of 500 of probably the most rapidly clicked Ars headlines from the previous 5 years and did some pure language processing on them. After stripping out the “cease phrases”—probably the most generally occurring phrases within the English language which might be sometimes not related to the theme of the headline—I generated a phrase cloud to see what themes drive probably the most consideration.
Right here it’s: the form of Ars headlines.
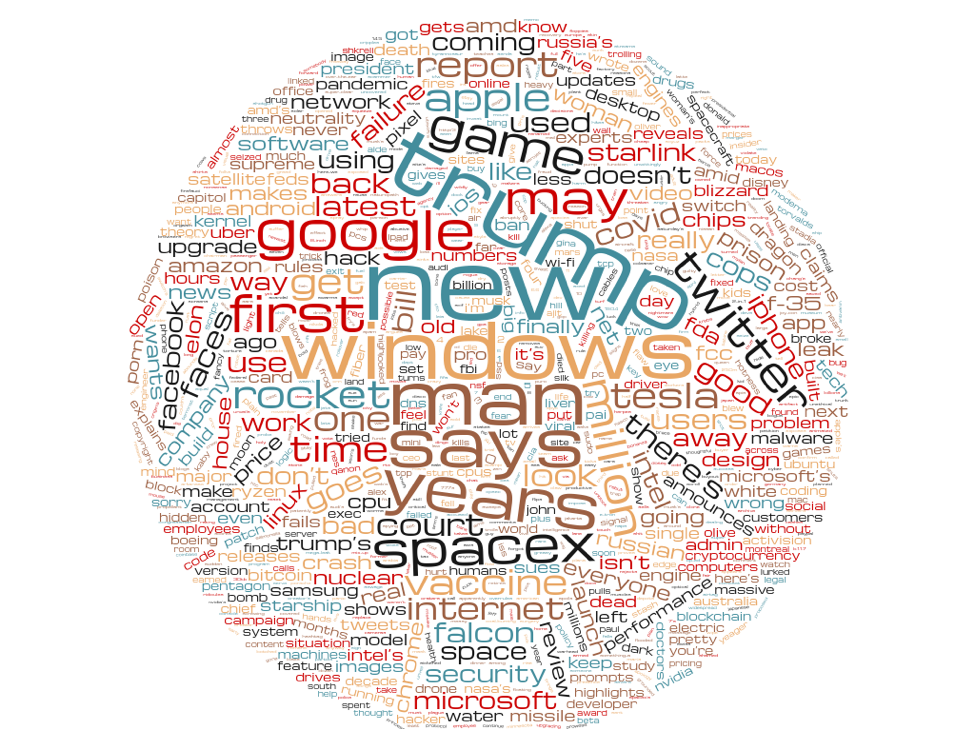
There’s a complete lot of Trump in there—the previous couple of years have included a variety of tech information involving the administration, so it is in all probability inevitable. However these are simply the phrases from a number of the profitable headlines. I wished to get a way of what the distinction between profitable and dropping headlines had been. So I once more took the corpus of all Ars headline pairs and break up them between winners and losers. These are the winners:

And listed below are the losers:
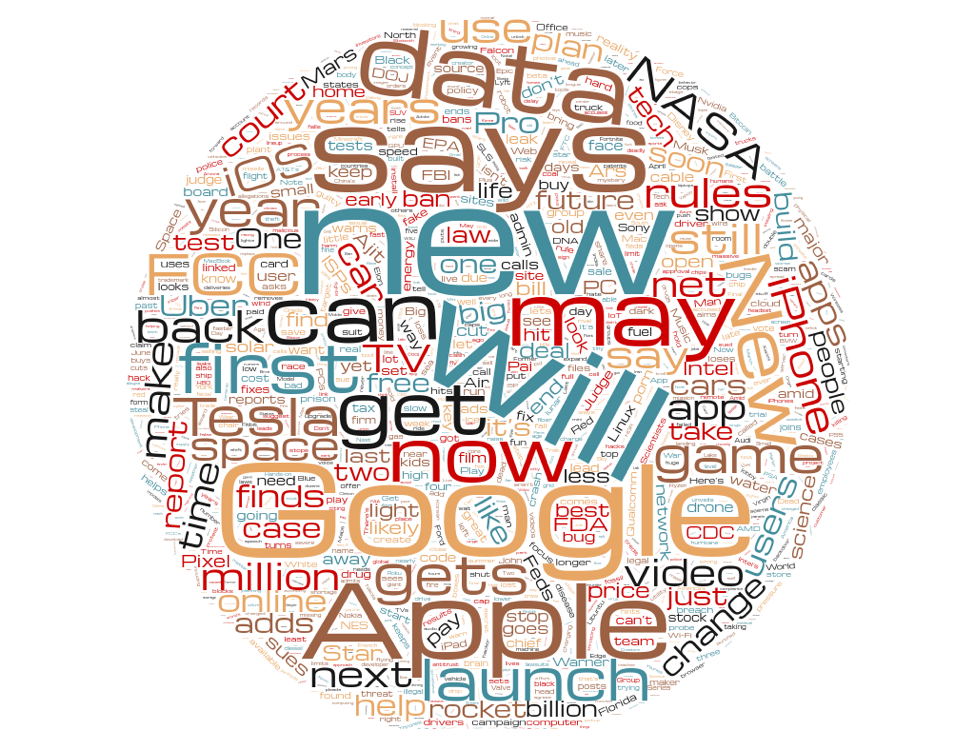
Do not forget that these headlines had been written for the very same tales because the profitable headlines had been. And for probably the most half, they use the identical phrases—with some notable variations. There’s an entire lot much less “Trump” within the dropping headlines. “Million” is closely favored in profitable headlines, however considerably much less so in dropping ones. And the phrase “might”—a reasonably indecisive headline phrase—is discovered extra incessantly in dropping headlines than profitable ones.
That is fascinating data, but it surely would not in itself assist predict whether or not a headline for any given story shall be profitable. Would it not be attainable to make use of ML to foretell whether or not a headline would get extra or fewer clicks? Might we use the collected knowledge of Ars readers to make a black field that would predict which headlines could be extra profitable?
Hell if I do know, however we’ll strive.
All this brings us to the place we at the moment are: Ars has given me information on over 5,500 headline assessments over the previous 4 years—11,000 headlines, every with their price of click-throughs. My mission is to construct a machine studying mannequin that may calculate what makes a great Ars headline. And by “good,” I imply one which appeals to you, expensive Ars reader. To perform this, I’ve been given a small funds for Amazon Internet Companies compute sources and a month of nights and weekends (I’ve a day job, in spite of everything). No drawback, proper?
Earlier than I began looking Stack Change and numerous Git websites for magical options, nonetheless, I wished to floor myself in what’s attainable with ML and take a look at what extra proficient individuals than I’ve already carried out with it. This analysis is as a lot of a roadmap for potential options as it’s a supply of inspiration.





